【必读】求解智能体的模型组合和算力分布:基于信息论的终极答案

aip_admin
最近斯坦福大学发表了一篇很好的论文《An Information Theoretic Perspective on Agentic System Design》,其主题是用信息论的方法指导智能体AI系统设计。原文思路新奇,但理论性太强。今天的一篇短文,结合之前刘老师的一篇文章(Agentic RAN:智能体时代的下一代无线接入网),分享下一个观点:如何用信息论的方法求解智能体的模型组合和算力分布。
1. 引言:用“做一锅好菜”的例子来解释构建一个智能体AI系统的模型选择难题
如果把构建智能体AI系统比作“做一锅好菜”。那怎么才能做好这锅菜呢?很多人第一反应是:
- 招一个更厉害的大厨(也就是使用更大的大模型),这锅好菜自然就能做好。
但实际情况往往不如预想的那样美好,一个厉害的大厨,如果忙于解决各种琐碎的问题:择菜、洗菜、切菜,这个大厨再强,也会被这样的琐碎小事拖垮,等真正到上灶台掌勺炒菜的时候,已经被累垮了。
与此类似的,很多人做智能体系统时,第一反应是“上更大的模型就完事”。但现实世界的输入更像一场信息洪水:语音、图片、网页、传感器、对话历史一起涌进来。再聪明的大模型,也会像上面孤军奋战的大厨一样,被这些太杂、太长、太吵的“信息噪声”拖垮。Stanford的这篇论文把这种“信息越多反而越糊”的失效模式叫作 context rot(上下文腐烂)。
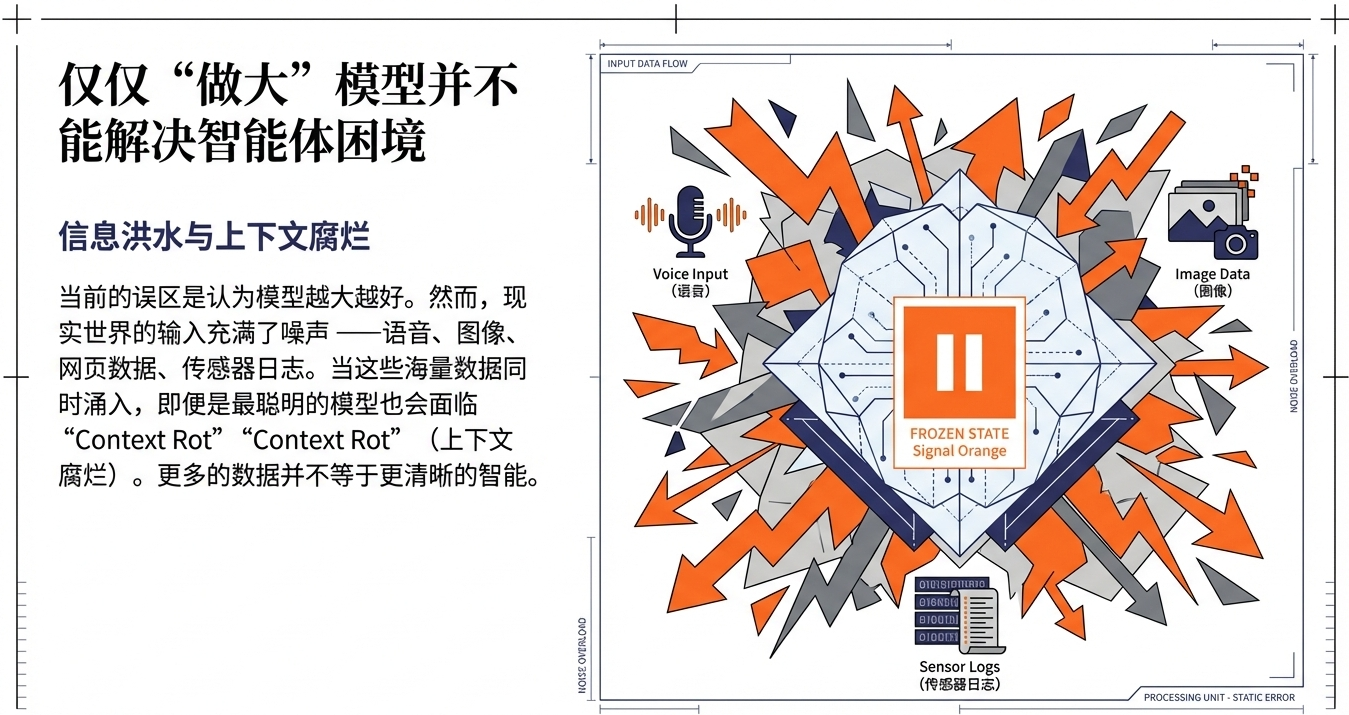
此时,就引出了一个关键问题:如果一个单一的大模型不能支撑一个好的智能体AI系统,那应该如何做?
2. 斯坦福论文的方案:“一个小的大模型+一个大模型”比“单一大模型”更能打
对于如何构建一个好的智能体AI系统,斯坦福的这篇论文,基于香农信息论(Shannon Information Theory)的理论方法进行研究,得到了一个很“反直觉但很工程”的答案:
- 别让一个大模型从头到尾包办;让一个合适规模的“小大模型”先做信息提纯(就像小厨师先做“择菜、洗菜、切菜”),再把精华交给大模型做终局推理(就像大厨师最后“爆炒出锅”)。这样反而更准、更稳,还更省。

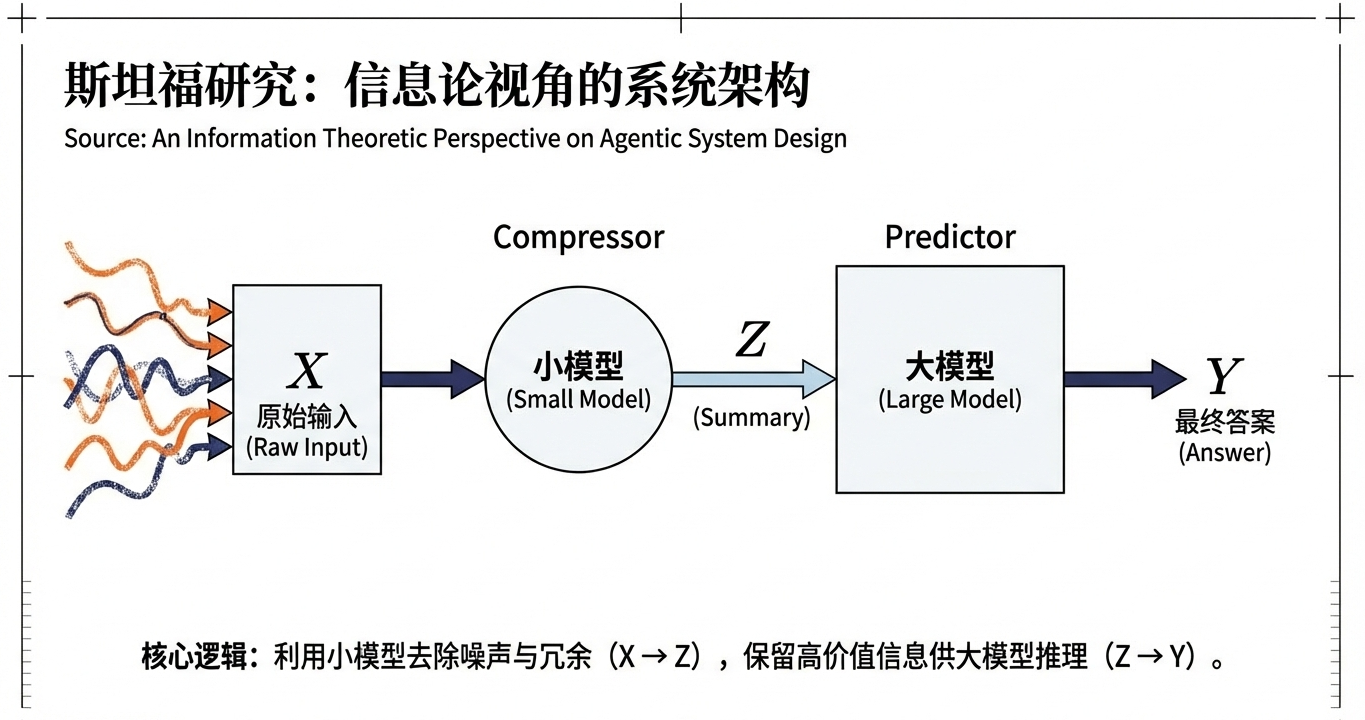
基于信息论原理,斯坦福论文把智能体AI系统抽象成同一个架构,由两个关键组件构成:
- 压缩器(compressor):较小的模型,把长输入 𝑋 提炼成短摘要 𝑍
- 预测器(predictor):较大的模型,基于短摘要 𝑍 输出最终答案 𝑌
用“做菜”类比:
- 压缩器:负责择菜、洗菜、切菜(去噪、去冗余、抓重点)
- 预测器:负责爆炒出锅(推理、规划、生成)
在此基础上,通过基于信息论理论基础的计算和实验,斯坦福论文给出一个很“硬”的经验结论:
- 把算力优先投在压缩器上,往往比继续堆预测器更划算。
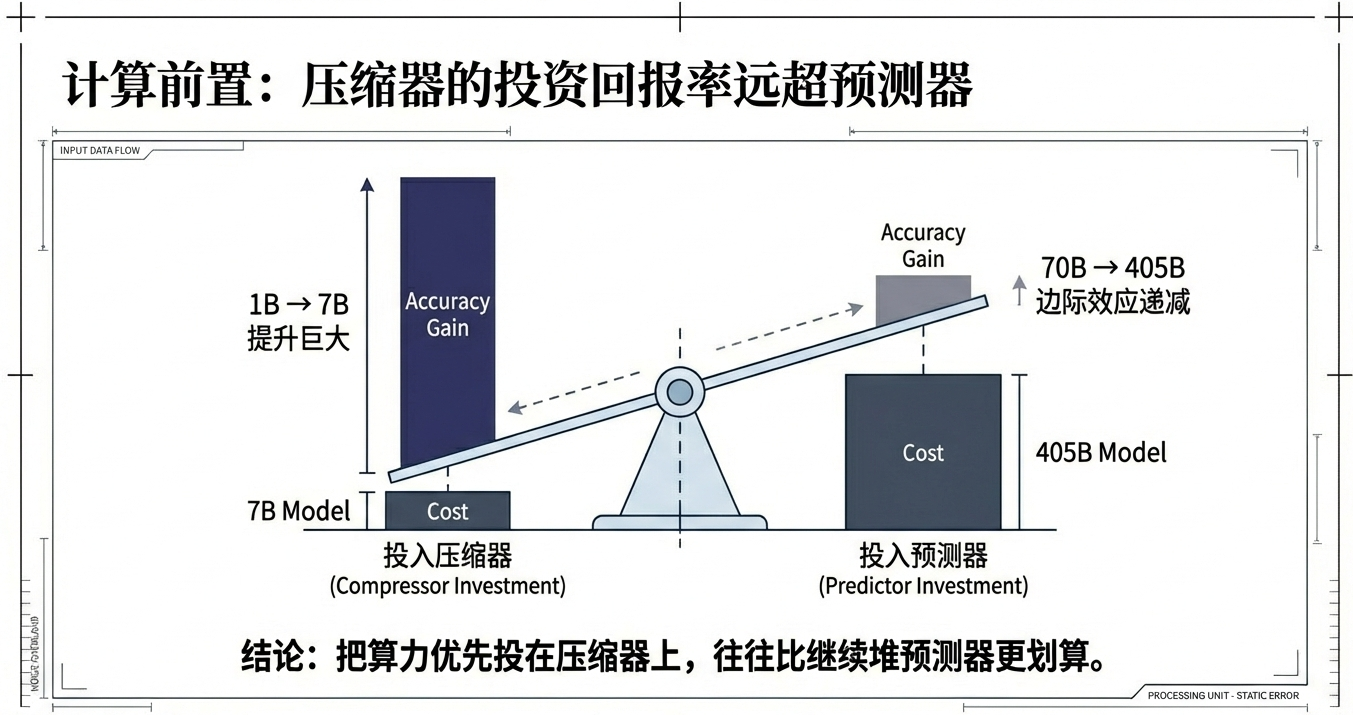
从论文的实验结果里可以看到:在某些任务上,压缩器从 1B 扩到 7B 带来的准确率提升远超把预测器从 70B 扩到 405B。
而且,“大一点的压缩器”不只是更准,还更省(节省上下文和token):
- 论文在摘要里直接给出例子:7B 的 Qwen-2.5 压缩器相对 1.5B,能做到更准确、更简洁,甚至“每个 token 携带的信息更多”。
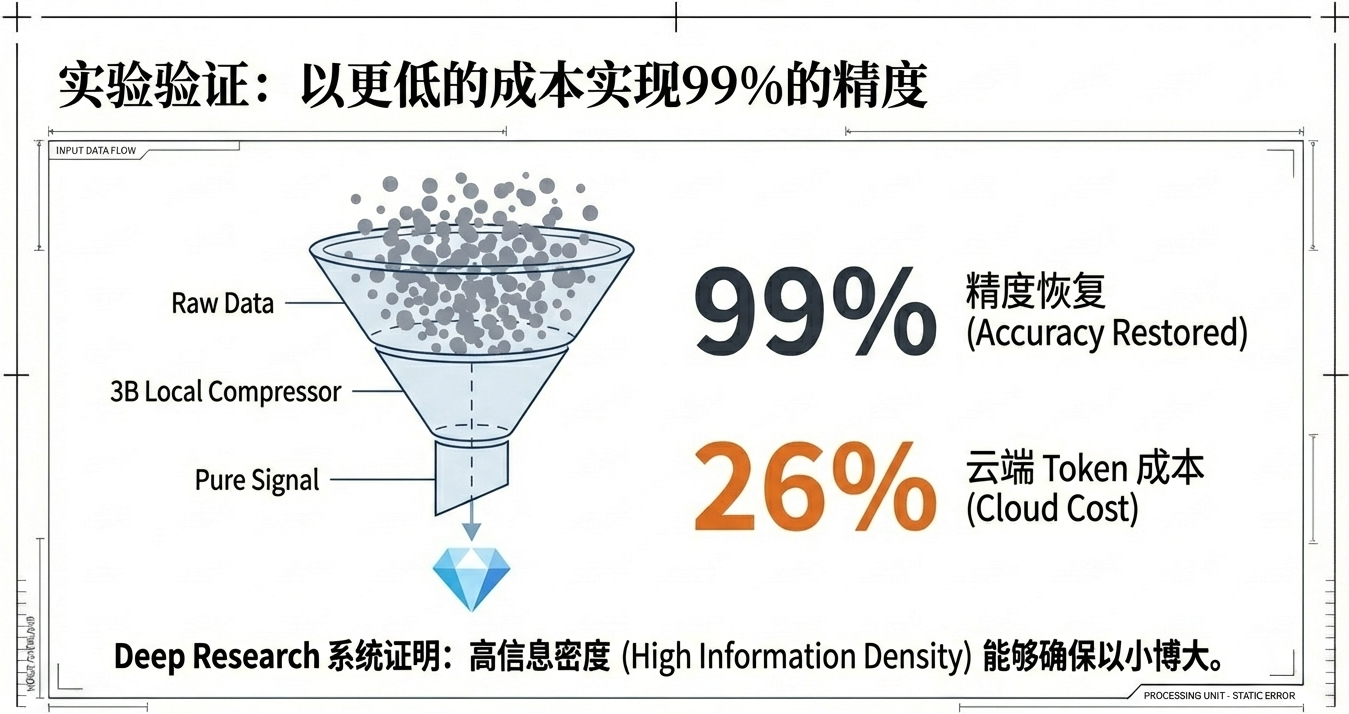
- 把这套原则放进 Deep Research 系统里,作者报告:3B 级别的本地压缩器可恢复 99% 前沿模型准确度,同时大模型调用的 token 成本降到 26%。
斯坦福论文把这些经验提炼为以下智能体AI系统的“设计原则”:
- 计算前置:把计算“前置”到压缩器,减少云端预测器成本
- 信息优化:前置压缩后的文本“信息含量/密度”越高,下游表现越稳
3. 斯坦福论文方法的落地方案:引入Agentic-RAN的“端-边-云”架构
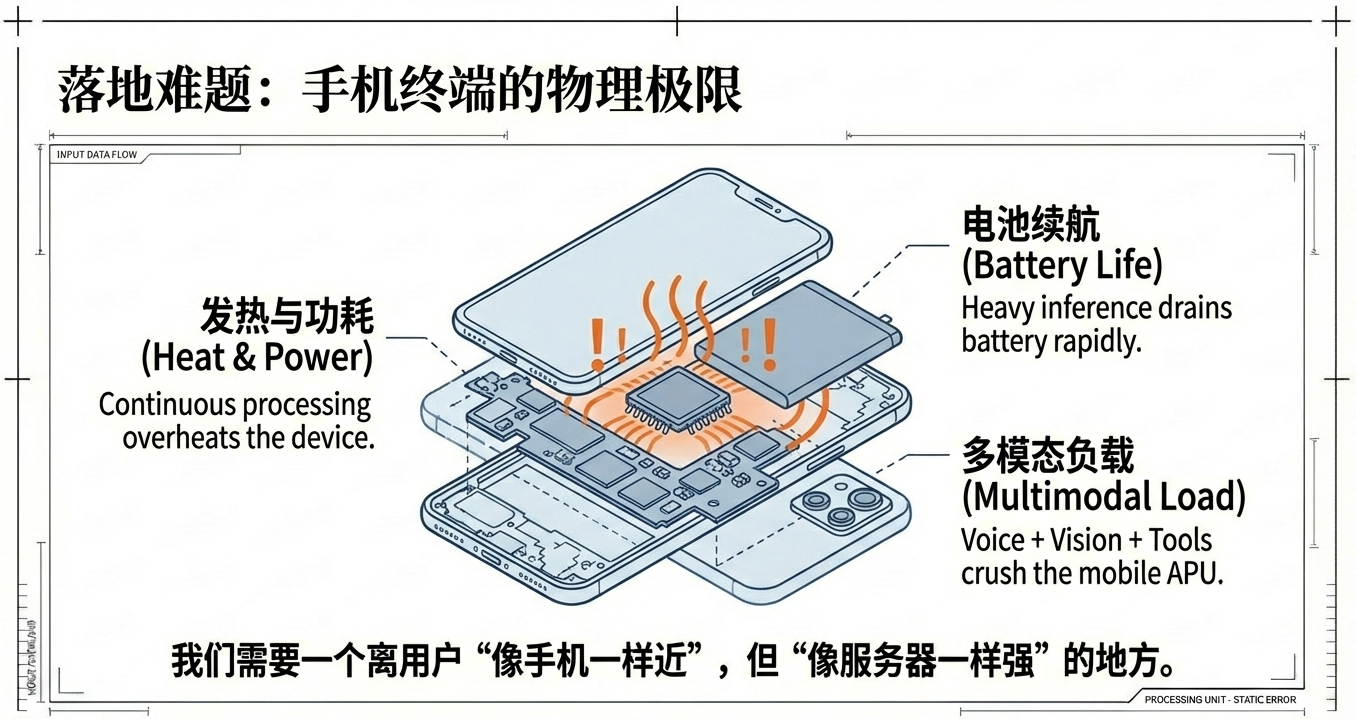
斯坦福论文提出了一套很好的经验方法,并且认为手机端是一个比较好的执行前置压缩器的位置。但是实际上,手机的端侧算力、能耗、发热、内存都是硬门槛。特别是多模态智能体(语音/视觉/检索/工具调用)并发时,端侧手机往往“顶不住”。
因此,引入Agentic-RAN的“端-边-云”智能体AI系统算力架构(Agentic RAN:智能体时代的下一代无线接入网),是一个具备实践意义的系统方案:- 网络不仅负责传输,还在基站/汇聚侧提供边缘 AI 算力与能力编排,形成云—边—端一体的“算力网络”。
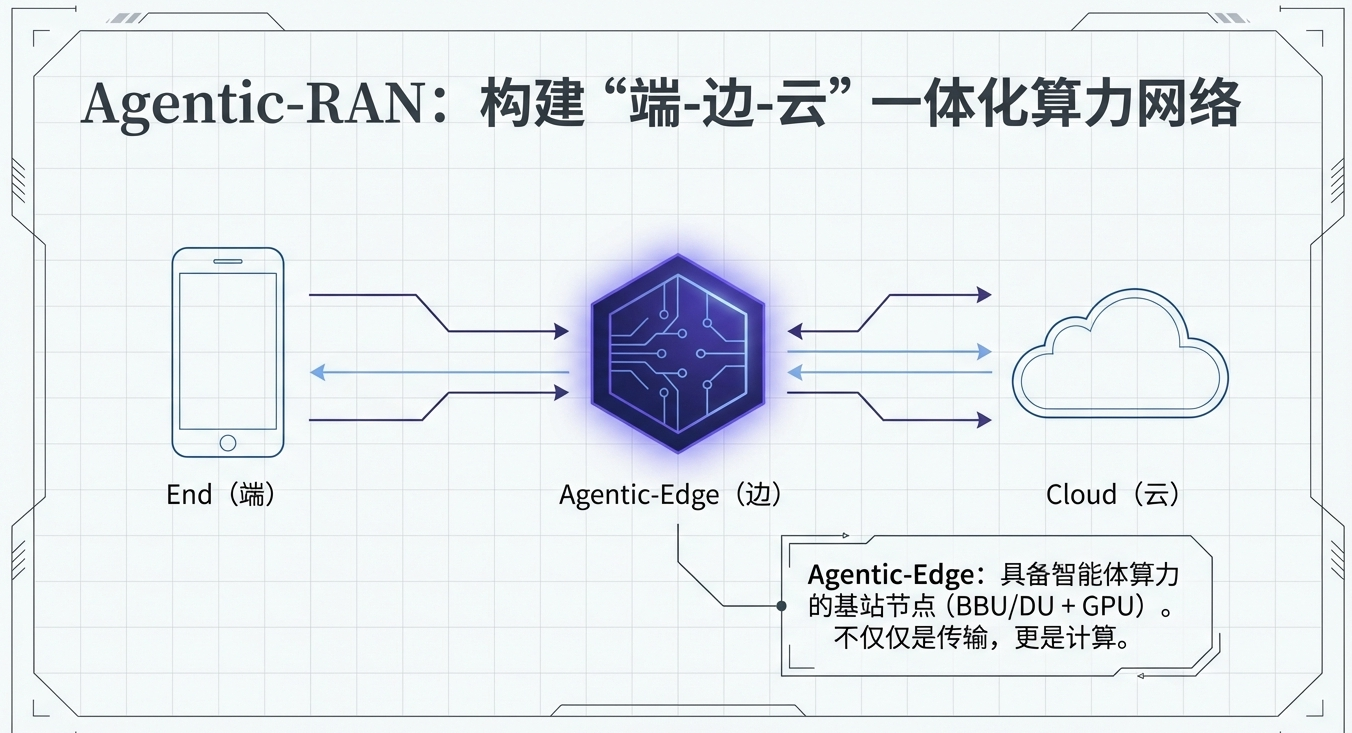
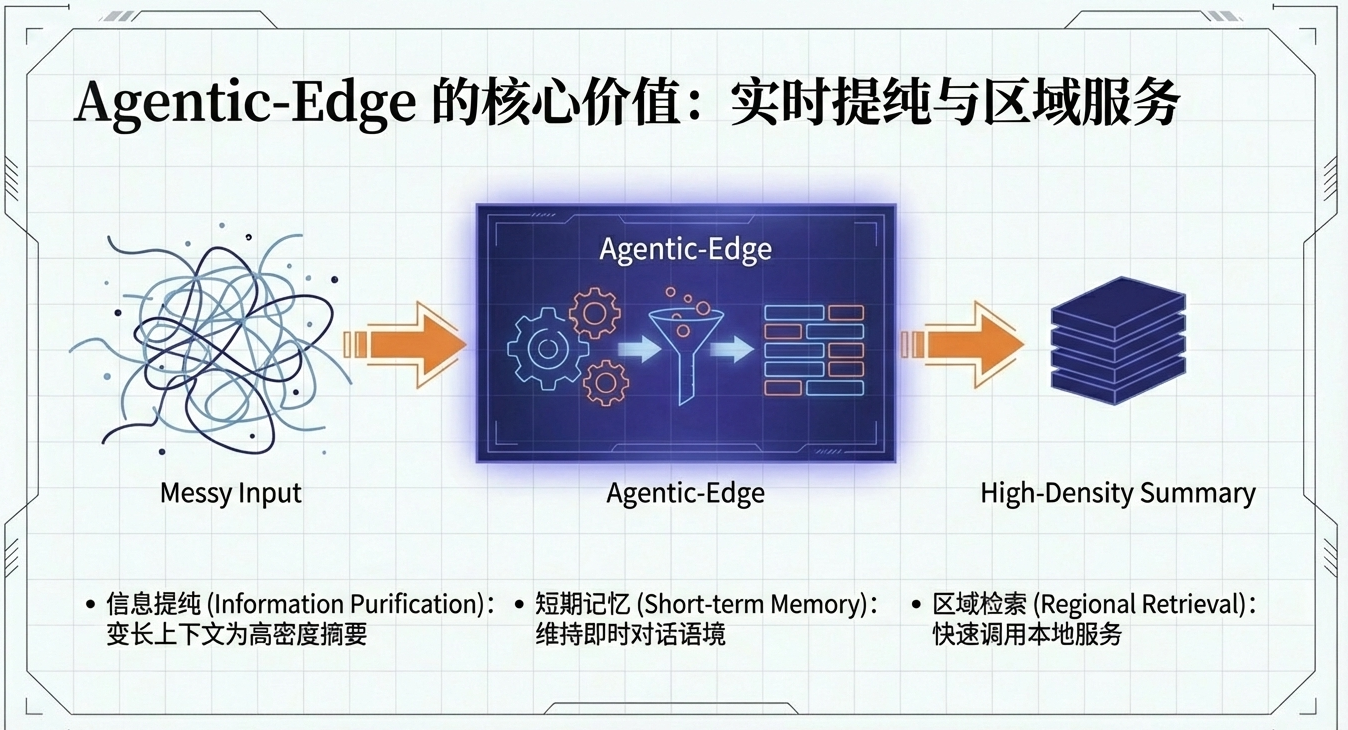
在Agentic-RAN中引入一个关键节点:Agentic-Edge——具备智能体算力与服务能力的 RAN 边缘节点。Agentic-Edge的一种实现方式是可以“插 GPU 卡并提供智能体运行环境的 BBU 或 DU”。由此形成一种协同的“端-边-云”架构:
- 端侧:隐私强、时延低,但算力有限、能耗敏感
- 边缘(Agentic-Edge):距离近、时延低、带宽充足,适合实时推理、短期记忆、区域检索与工具代理
- 云侧:算力最强、知识最全,适合大模型重推理、长链路规划与全局更新
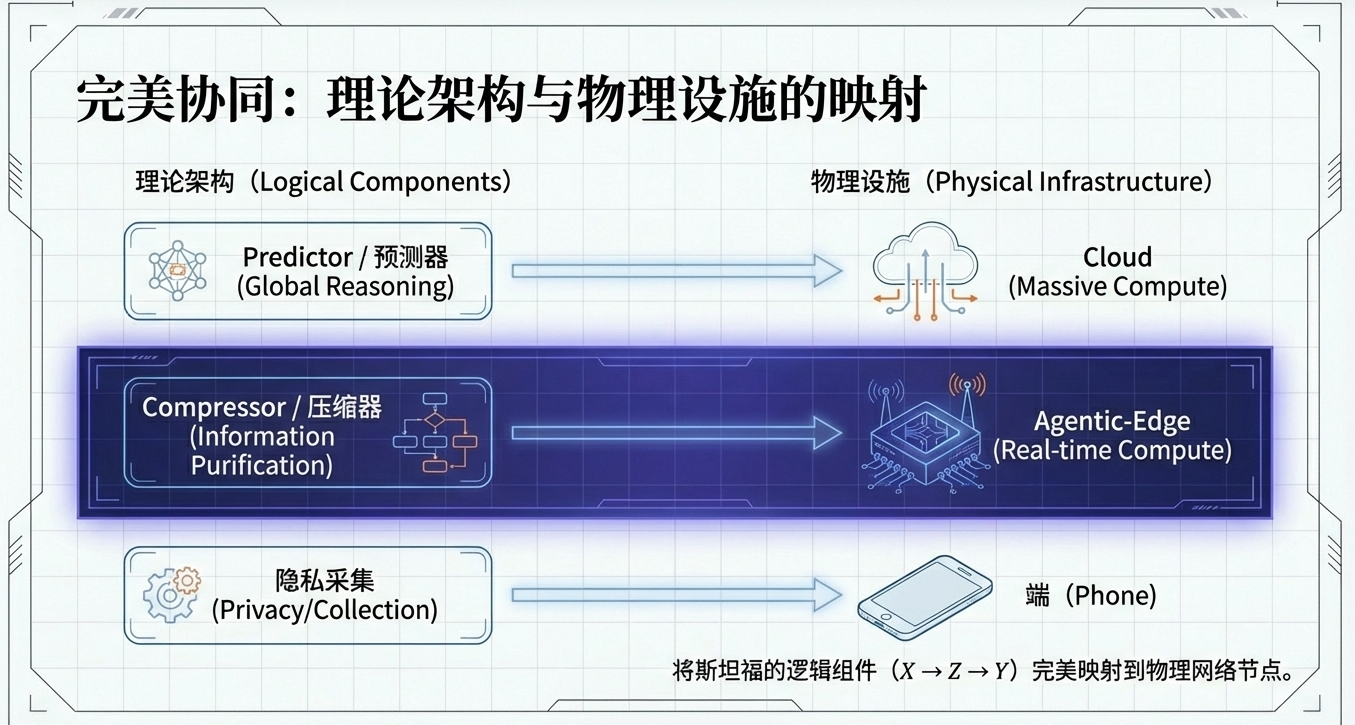
把斯坦福论文提出的“压缩—预测”和 Agentic RAN 的“云—边—端”架构叠加到一起,就得到一个实践性极强的智能体AI系统部署方案:
- 手机端:采集与最轻量的预处理(含隐私控制)
- 边缘端(Agentic-RAN/Agentic-Edge):跑“小大模型”做压缩/提纯,把杂乱长上下文变成“高信息密度摘要”
- 云端:跑“大模型”做最终推理、规划与生成
4. 结语:用信息论方法,把智能体AI系统的“模型组合+算力分布”难题变成可解的算术题
把斯坦福最新论文和Agentic-RAN方案结合起来,我们可以用科学的信息论方法,把复杂的智能体AI系统的“模型组合+算力分布”难题,转变为一道可解的算术题:
- 智能体AI系统真正的瓶颈,常常不是“模型不够大”,而是信息没有被提纯、传递和消费得足够高效;
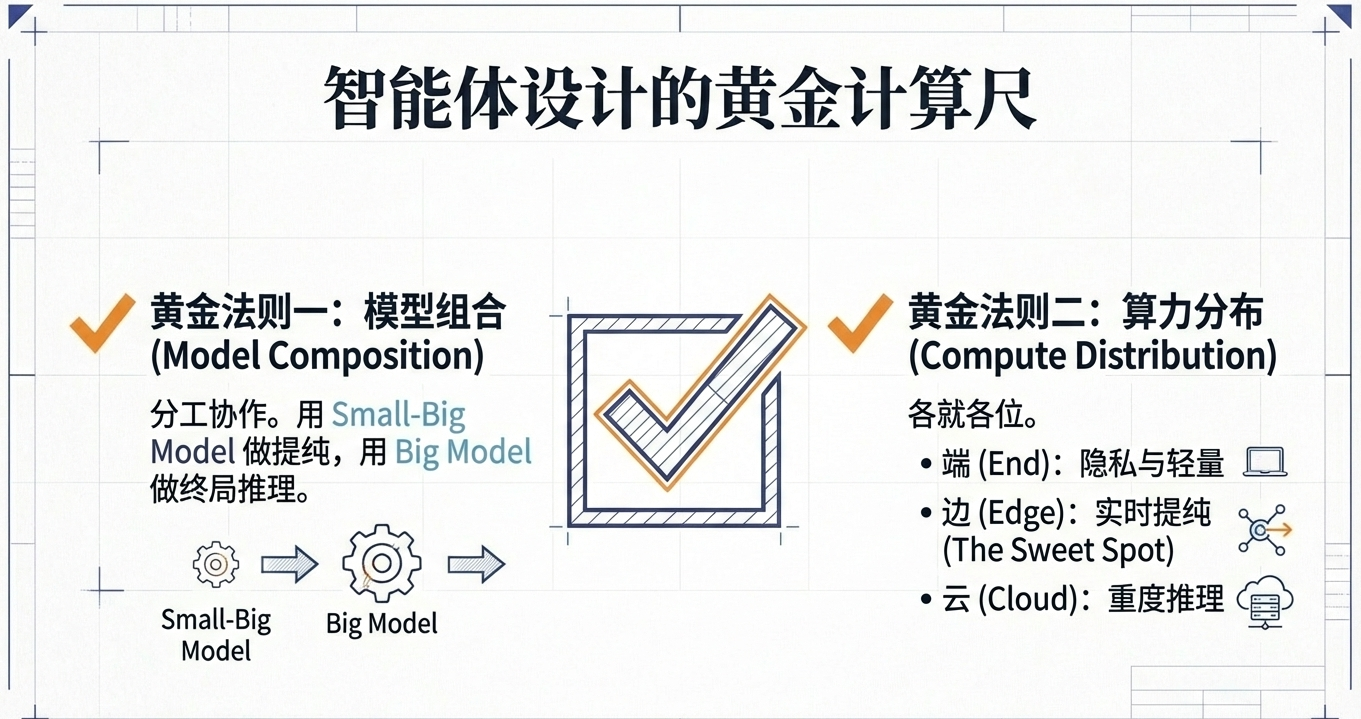
- 因此,模型组合要学会分工:小大模型做提纯,大模型做终局推理;
- 算力分布要学会就位:端侧做轻与隐私,边缘做实时提纯与就近服务,云侧做重推理与全局能力。
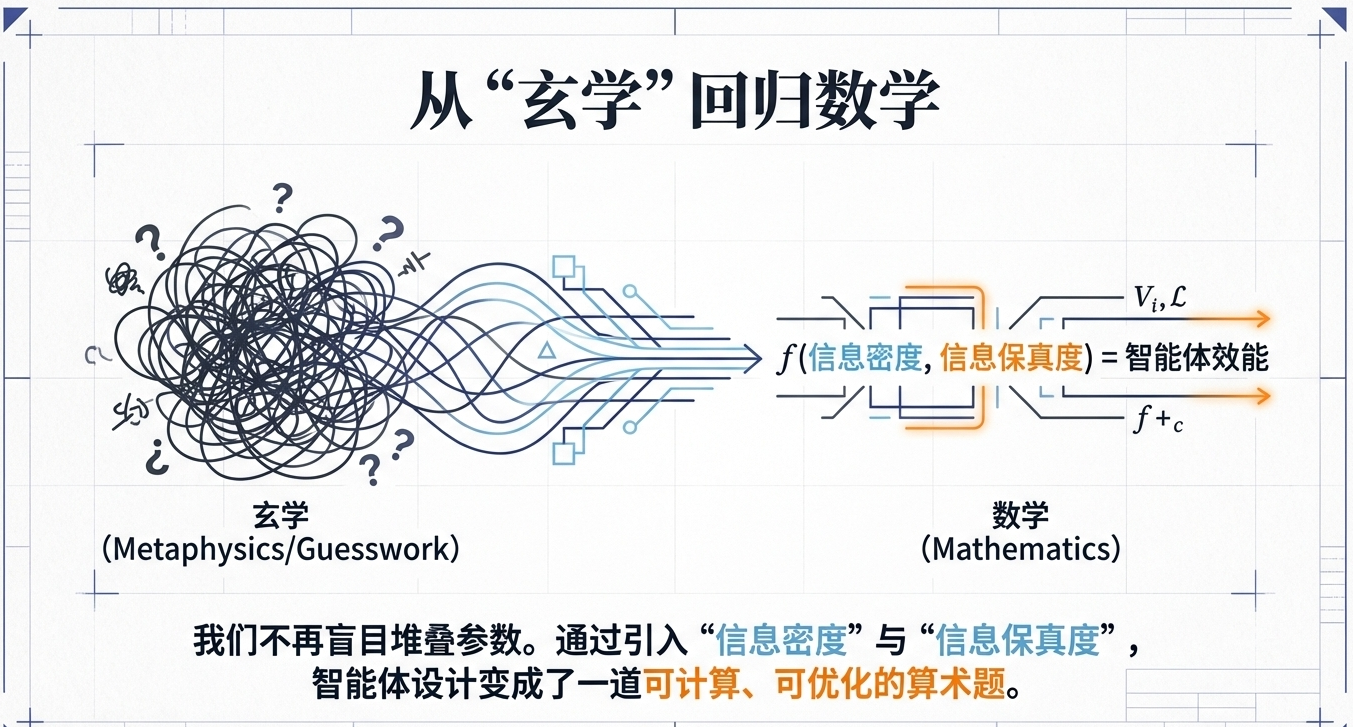
基于信息论的“信息密度/信息保真”理论方法对上述问题进行求解,我们可以将目前的智能体AI系统模型组合和算力分布设计的玄学问题,转化为能持续迭代的数学问题,这将会是智能体AI系统落地的黄金计算尺。